WiCLP: Window-Based Compositional Linear Projection
we propose Window-based Compositional Linear Projection (WiCLP), a lightweight fine-tuning method that significantly improves the model’s performance on compositional prompts, yielding results comparable to existing baselines. WiCLP obtains new embeddings for tokens in the input prompt by applying a linear projection on tokens in conjunction with a set of their adjacent ones, i.e., tokens within a specified window. This method uses linear projection and contextual cues from neighboring tokens to refine CLIP text encoder embeddings, producing embeddings that more effectively capture the compositional scene.
(i) WiCLP improves Compositionality!










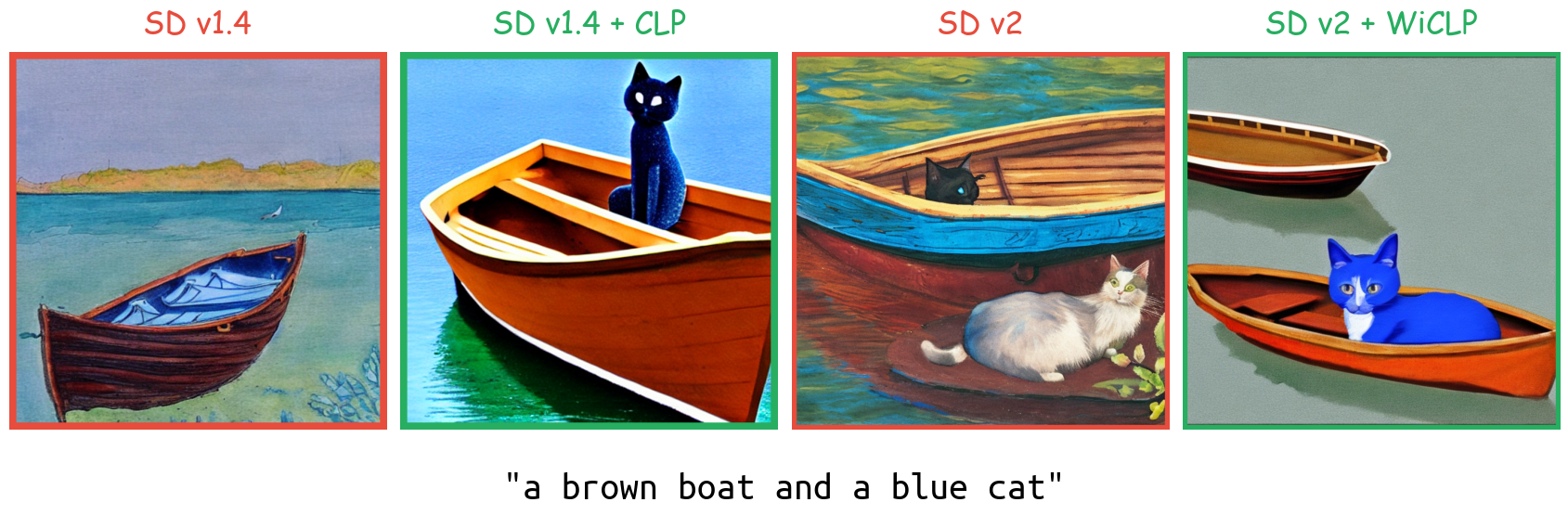









(ii) WiCLP improves Cross-Attention Masks!






(iii) Switch-Off enables WiCLP to preserve Model Utility!
















Fine-tuning models or adding modules to a base model often results in a degradation of image quality and an increase in the Fréchet Inception Distance (FID) score. To balance the trade-off between improved compositionality and the quality of generated images for clean prompts --an important issue in existing work-- Inspired by Hertz et al [1], we adopt Switch-Off, where we apply the linear projection only during the initial steps of inference. More precisely, given a time-step threshold τ, for t ≥ τ, we use WiCLP, while for for t < τ, we use the unchanged embedding (output of CLIP text encoder) as the input to the cross-attention layers. As seen above, τ = 800 provides a correct compositional scene while preserving the quality.
Possible Sources of Compositional Issues
We investigate two possible sources of compositionality issues in text-to-image models.
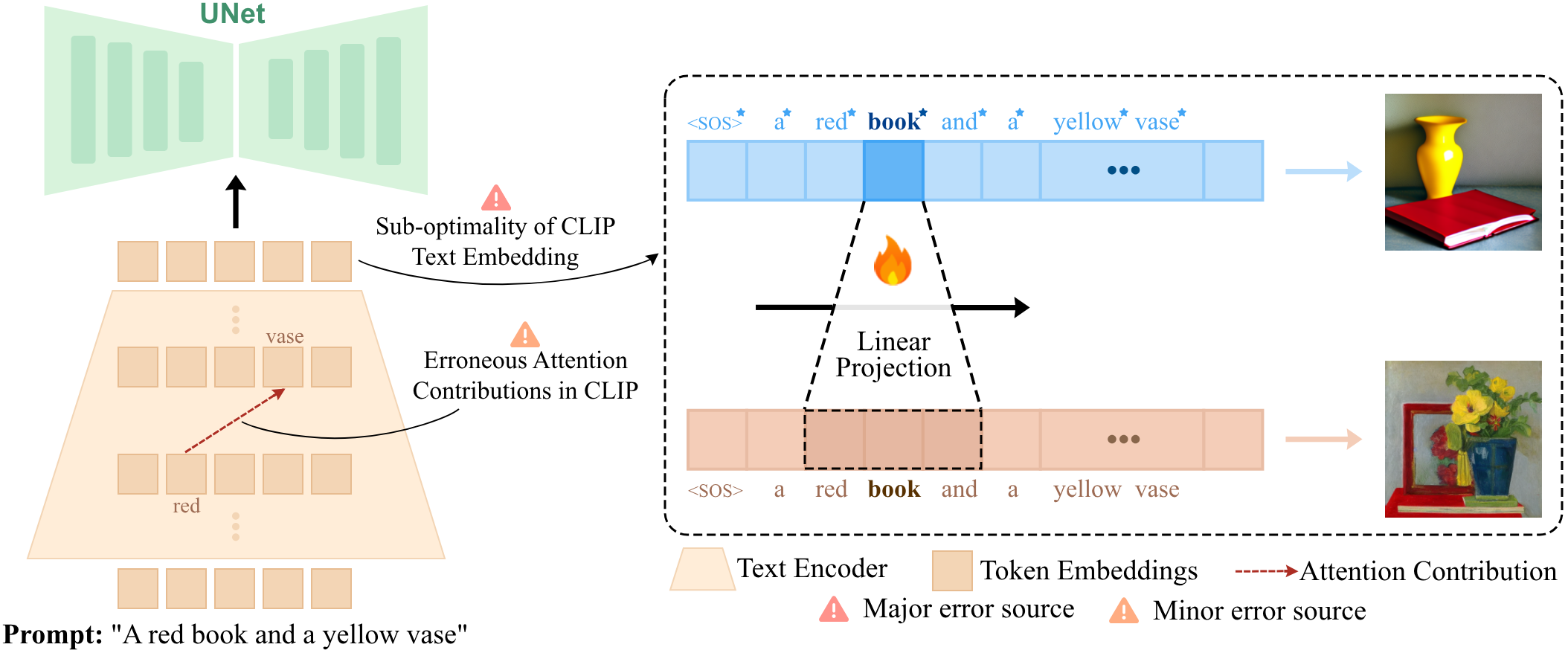
Source (i): Errorneous Attention Contributions in CLIP Text Encoder
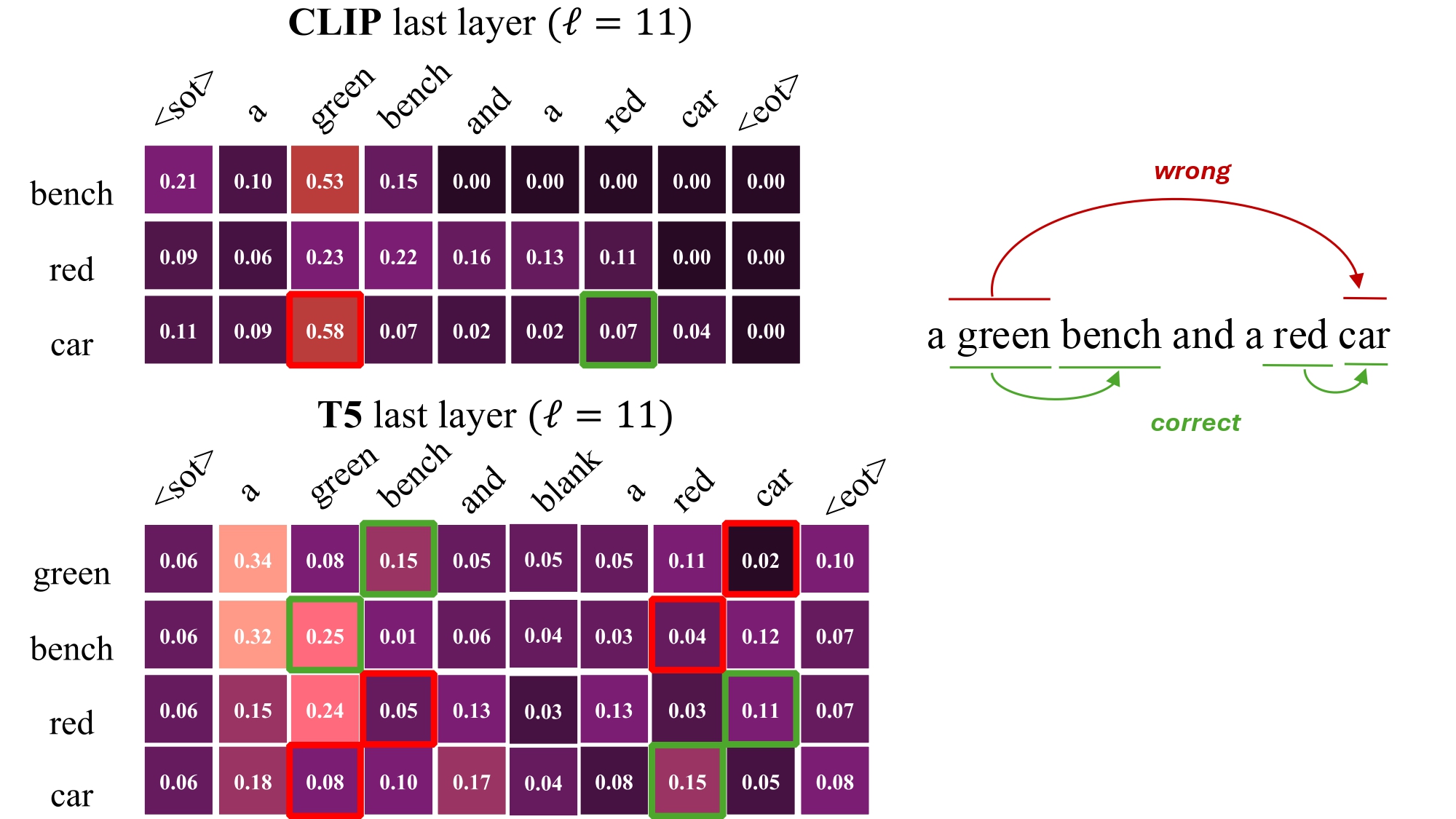
Above Figure visualizes the attention contribution of both T5 and CLIP text-encoder in the last layer ℓ = 11 for the prompt "a green bench and a red car". Ideally, the attention mechanism should guide the token "car" to focus more on "red" than "green", but in the last layer of the CLIP text-encoder, "car" significantly attends to "green". In contrast, T5 shows a more consistent attention pattern, with "red" contributing more to the token "car" and "green" contributing more to the token "bench".
Source (ii): Sub-Optimality of CLIP Text-Encoder
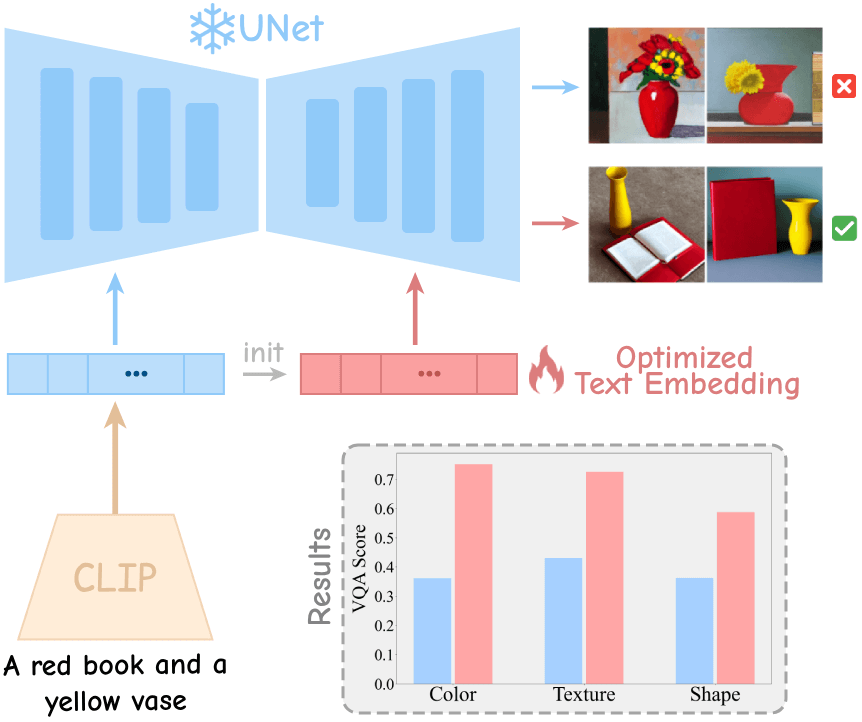
we observe that the UNet is capable of generating compositional scenes if propoer text-embeddings is given as the input. This proper embedding is obtained by freezing the UNet and optimizing diffusion loss over images with high VQA scores, using the text embedding as the optimization variable. We consistently improve VQA scores across a variety of compositional prompts (i.e., color, texture, and shape). This indicates that CLIP text-encoder does not output the proper text-embedding suitable for generating compositional scenes. However, that optimized embedding space exists, highlighting the ability of UNet to generate coherent compositional scenes when a proper text-embedding is given.
WiCLP Achieves Superior Compositional Performance on Stable Diffusion Models in T2I-CompBench!
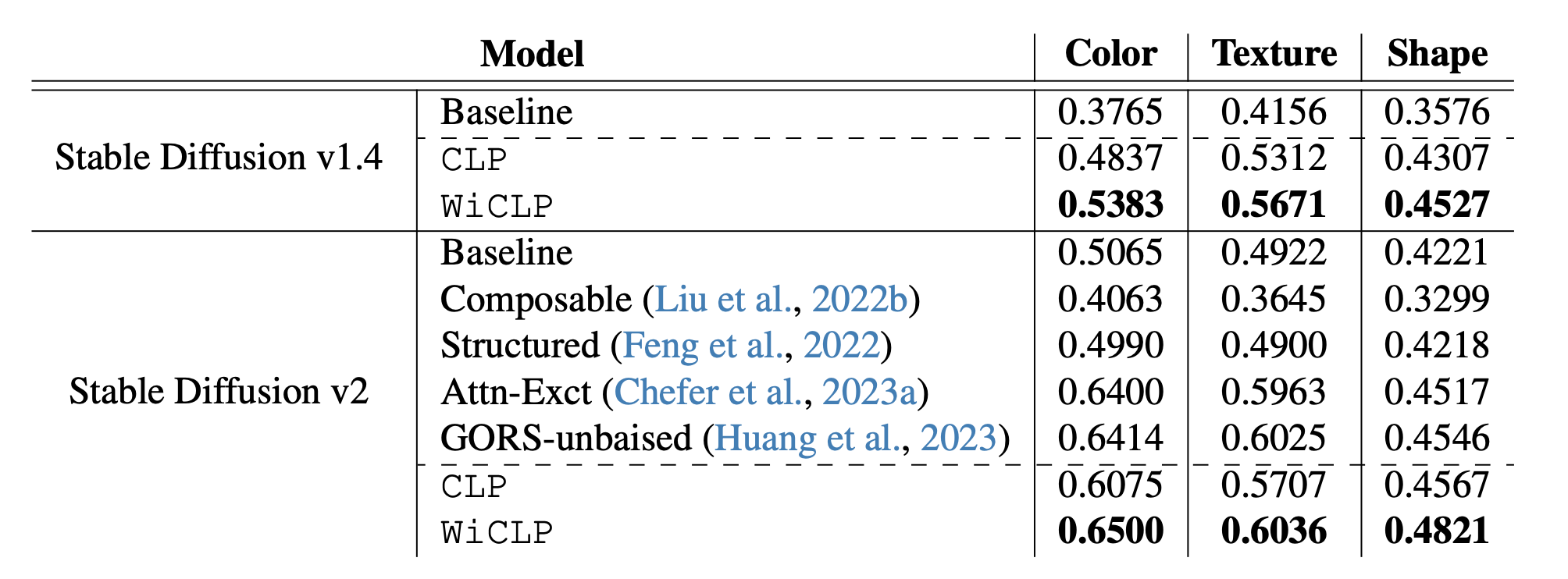
VQA scores of our method and other discussed baselines are provided in above Table. As shown, WiCLP significantly improves upon the baselines and achieves higher VQA scores compared to other state-of-the-art methods, despite its simplicity.